The Architecture of Understanding: Two Planes, One Platform, Zero Compromises
"Make everything as simple as possible, but not simpler." — Albert Einstein
Reading time: 14 minutes Series: The Matih Platform Blog Series (2 of 8) Audience: Architects, Senior Engineers, Technical Evaluators

The Most Expensive Mistake in Platform Design
There's a pattern in enterprise software that kills platforms before they ship. It goes like this:
A team builds a monolith. It works beautifully for the first three customers. By customer twenty, deployments take four hours. By customer fifty, one tenant's runaway query brings down the billing system. By customer one hundred, the team is planning "the rewrite."
The opposite mistake is equally deadly: decompose too early, into too many services, without clear boundaries. You end up with a distributed monolith — all the complexity of microservices, none of the benefits. Services call each other in circles. A single request touches twelve databases. Nobody can explain what happens when you click "Run Query."
Matih chose a third path. Not monolith. Not microservice soup. A two-plane architecture — a structural pattern borrowed from Kubernetes itself and proven at planetary scale — that draws exactly one clean line through the entire system.
That line separates management from execution. And everything else follows from there.
The Line That Changes Everything
Picture this: on one side, everything that runs the platform — identity, tenant management, billing, configuration, auditing, observability. On the other side, everything that runs your workloads — queries, AI agents, ML training, pipelines, dashboards.
Control Plane: "Who are you? What are you allowed to do? How much have you used?" Data Plane: "Here's your query result. Here's your chart. Here's your trained model."
| Dimension | Control Plane | Data Plane |
|---|---|---|
| Job | Manage the platform | Execute your work |
| Tech stack | Java / Spring Boot 3.2 (uniform) | Java, Python, Node.js (polyglot) |
| Scales with | Number of tenants | Volume of workloads |
| Touches your data? | Never. Platform metadata only. | Always. That's its entire purpose. |
| If it goes down | Management paused, workloads continue | Workloads paused, management continues |
| Failure blast radius | Configuration, auth, billing | Queries, dashboards, ML jobs |
This isn't just a diagram convention. It's an architectural invariant — a rule that shapes deployment topology, security boundaries, failure domains, and scaling strategies. And it's the reason Matih can serve a hundred tenants without any of them knowing the others exist.
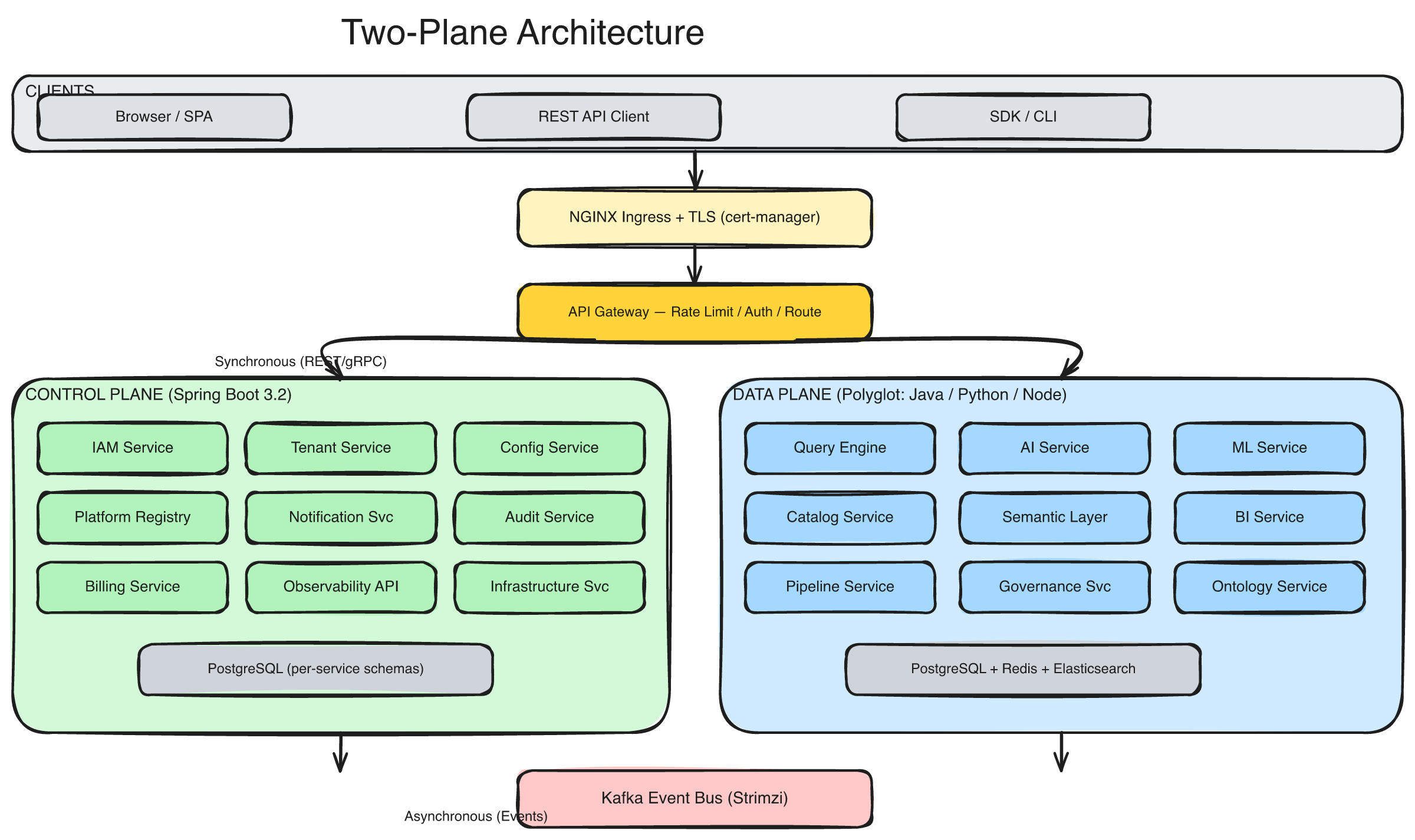
The two-plane architecture: clients hit the API Gateway, which routes to either the Control Plane (platform operations) or the Data Plane (tenant workloads). Synchronous REST flows up, asynchronous Kafka events flow across the bottom.
The Control Plane: Running the Railroad
The Control Plane is 10 services, all built in Java 21 with Spring Boot 3.2, living in a single Kubernetes namespace. It's deliberately homogeneous — one language, one framework, one set of conventions — because platform management services need to be boring. Reliable. Predictable. The kind of code that runs for months without anyone thinking about it.
Here's what each service does (and why it exists separately):
IAM Service — The security foundation. Handles login, JWT token issuance, role-based access control, API keys, MFA, and OAuth2 flows. Every other service in the platform trusts the tokens this service signs. It's the single source of identity truth.
Tenant Service — The largest and most complex control plane service. Manages the complete tenant lifecycle: creation, provisioning (a 56-step automated pipeline), tier management, DNS zones, custom domains, branding, and eventual decommissioning. When a new tenant signs up, this service orchestrates everything from namespace creation to TLS certificate issuance.
Config Service — Centralized configuration management with hierarchical overrides: platform defaults, then environment-specific settings, then tenant-specific customizations. Changes propagate to running services without restarts.
Billing Service — Usage metering, subscription management, cost tracking. Every query, every API call, every GB of storage gets metered and attributed to the right tenant.
Audit Service — An immutable audit trail. Every significant action across the entire platform — every login, every query, every configuration change — is recorded with who, what, when, and from where. This isn't optional. It's structural. SOC 2 auditors love it.
Notification, Observability API, Infrastructure, Platform Registry — Rounding out the platform concerns: multi-channel alerting, metrics aggregation, infrastructure provisioning, and a service catalog that knows what's running where.
Why Homogeneous?
A common question: why force Java/Spring Boot for all control plane services? Why not use Python for the notification service or Go for the API gateway?
Because cognitive overhead compounds. When every control plane service shares the same language, framework, commons library, build tool, deployment pattern, and debugging approach, any engineer can jump into any service. The commons-java library provides over 100 shared classes — JWT validation, tenant context propagation, structured logging, circuit breakers, health checks — so each service inherits battle-tested infrastructure without reinventing it.
One language. One framework. One way of doing things. For platform management code, that's a feature, not a limitation.
The Data Plane: Where Work Actually Happens
The Data Plane is where things get interesting. It's 14 services spanning three languages — Java for data-intensive operations, Python for AI/ML, Node.js for rendering — because workload diversity demands technology diversity.
You wouldn't write an LLM orchestrator in Java. You wouldn't train a neural network in Node.js. You wouldn't do server-side chart rendering in Python. The Data Plane is deliberately polyglot because each service's technology choice is driven by its problem domain, not by organizational uniformity.
Here's the lineup:
The Query Layer
-
Query Engine (Java) — The SQL execution layer. Receives queries (human-written or AI-generated), validates them, routes to the optimal execution backend (Trino for federated SQL, ClickHouse for OLAP, DuckDB for lightweight), caches results at three levels, and enforces row-level security. Every query is tenant-isolated, resource-governed, and audited.
-
Catalog Service (Java) — The metadata brain. Knows every table, every column, every relationship, every data quality score. Automatically discovers schemas, tracks lineage, and syncs with OpenMetadata. When the AI generates SQL, this is where it gets its map of the data landscape.
-
Semantic Layer (Java) — The business logic home. Defines reusable metrics ("Revenue = SUM(order_total) WHERE status = 'completed'"), dimension hierarchies (Year > Quarter > Month > Day), and access policies. This is what makes "show me revenue by region" work — the semantic layer translates business language into precise SQL.
The Intelligence Layer
-
AI Service (Python) — The flagship. 984 source files. A LangGraph multi-agent orchestrator with specialized agents for routing, SQL generation, analysis, visualization, and documentation. Handles text-to-SQL with vector-based schema retrieval (Qdrant), streaming responses via WebSocket, and multi-turn conversational context.
-
ML Service (Python) — Full MLOps lifecycle. Experiment tracking via MLflow, distributed training via Ray, model registry with promotion workflows, real-time serving with A/B testing and canary deployments, feature store via Feast, and drift detection.
-
Ontology Service (Python) — Domain knowledge models. Entity types, relationships, semantic mappings, SHACL validation. This is what turns "customer" from an ambiguous word into a precise entity with defined attributes and relationships across the data landscape.
The Operations Layer
-
Pipeline Service (Python) — Orchestrates data workflows across four engines: Airflow for batch ETL, Spark for large-scale processing, Flink for real-time streaming, and Temporal for long-running stateful workflows. One API, four engines, unified monitoring.
-
Data Quality Service (Python) — Continuous quality monitoring. Rule-based validation, statistical profiling, anomaly detection, quality scoring. When data goes bad, this service knows first.
-
Governance Service (Python) — Policy enforcement. Attribute-based access control, row-level security policies, data masking rules, sensitive data discovery, compliance reporting.
The Experience Layer
-
BI Service (Java) — Dashboard lifecycle management. CRUD, widget system, scheduled refresh, sharing, embedding. Works hand-in-hand with the semantic layer.
-
Render Service (Node.js) — Server-side chart rendering, PDF generation, thumbnail creation. The reason exported dashboards look exactly like they do on screen.
-
Ops Agent, Data Plane Agent — AI-powered operations diagnostics and local health management.
The Glue: How the Planes Talk
Two planes need two communication patterns:
Synchronous REST (When You Need the Answer Now)
A user asks a question. The browser hits the API Gateway. The gateway routes to the AI service. The AI service calls the catalog for schema context, calls the query engine to execute SQL, calls the semantic layer for metric definitions. The response streams back. Total time: seconds.
This is the request-response path. It's synchronous because the user is waiting. Every hop carries a JWT token. Every service validates tenant context. Every call has circuit breakers and retry policies.
Asynchronous Kafka (When You Don't)
A query completes. The query engine publishes a QUERY.COMPLETED event to Kafka. The audit service picks it up and logs it. The billing service picks it up and meters it. The context graph service picks it up and updates relationships. The data quality service checks the results. None of these need the query engine to wait.
This is the event-driven path. Kafka (via Strimzi operator) serves as the central nervous system — 20+ event categories flowing between services. Every event carries a tenant ID, a correlation ID, and a timestamp. Events are immutable, ordered, and replayable.
The principle is simple: if the caller needs to wait for the result, use REST. If it can proceed without the result, use events.
This dual-pattern approach gives the platform both low-latency request handling and reliable asynchronous processing without forcing either pattern where it doesn't fit.
Namespace Topology: Security Through Structure
The platform uses seven Kubernetes namespaces, and the boundary choices are deliberate:
| Namespace | What Lives Here | Why It's Separate |
|---|---|---|
matih-system | Operators, CRDs, Strimzi, cert-manager | Infrastructure components with cluster-wide permissions |
matih-control-plane | All 10 CP services | Management services share fate and scale together |
matih-data-plane | Data Plane services (per-tenant in production) | Workload isolation — one tenant can't impact another |
matih-observability | Prometheus, Grafana, Loki, Tempo | Monitoring must survive what it monitors |
matih-monitoring-cp | Control Plane ServiceMonitors | Monitoring config separated from monitored services |
matih-monitoring-dp | Data Plane ServiceMonitors | Same principle for Data Plane |
matih-frontend | React workbench applications | Frontend deploys independently of backend |
In production, each tenant gets its own namespace: matih-data-plane-{tenant-slug}. That namespace contains the tenant's Data Plane services, secrets, resource quotas, network policies, and nothing else. Kubernetes NetworkPolicies enforce that pods in one tenant's namespace cannot reach pods in another's. This isn't application-level security — it's infrastructure-level isolation.
The Commons Libraries: Consistency Without Monolith
How do you keep 24 services consistent without coupling them together? Through shared libraries that establish conventions:
commons-java — 100+ classes covering JWT validation, tenant context propagation (TenantContext.getCurrentTenantId()), structured logging with tenant enrichment, circuit breakers, retry policies, health check registration, Kafka event producers/consumers, and cache management. Every Java service inherits this.
commons-python — Tenant middleware, JWT decoding, structured logging (structlog), health check patterns. Every Python service inherits this.
commons-typescript — API client utilities, authentication hooks, shared UI components. Every frontend workbench inherits this.
commons-ai — LLM abstractions, prompt management, RAG utilities, agent framework. Shared across AI/ML services.
The key insight: these libraries enforce behavior (how to validate a token, how to propagate tenant context, how to structure a log line) without enforcing architecture (each service still owns its domain logic, data model, and API surface).
Design Trade-Offs: The Honest Version
Every architecture involves trade-offs. Here are the ones Matih made consciously:
24 Microservices: Worth the Complexity?
The cost: Distributed systems are harder. Network partitions happen. Distributed debugging requires tracing infrastructure. Deployment coordination requires tooling.
The payoff: Independent deployment (ship the AI service without touching billing). Technology diversity (Python for ML, Java for data). Fault isolation (a crashed render service doesn't take down authentication). Team autonomy (different teams own different services).
The mitigation: Commons libraries for consistency. A single components.yaml as the source of truth. 55+ Helm charts with standardized structure. Full observability (Prometheus + Grafana + Tempo + Loki) that makes distributed debugging tractable.
Polyglot: Three Languages Are Better Than One?
The cost: Different build tools, different container images, different debugging approaches, different dependency ecosystems.
The payoff: Java's Spring ecosystem is unmatched for enterprise data services (JDBC, Hibernate multi-tenancy, Spring Security). Python's ML ecosystem is irreplaceable (LangChain, PyTorch, scikit-learn, pandas). Node.js excels at server-side rendering. Forcing a single language would mean worse outcomes in at least two of these domains.
The mitigation: Commons libraries ensure behavioral consistency regardless of language. Cross-language contracts are defined through shared event schemas and OpenAPI specifications.
Hybrid Communication: REST + Kafka Is More Complex Than Either Alone
The cost: Two communication paradigms to understand, debug, and operate.
The payoff: Low-latency synchronous flows for interactive use cases. Reliable asynchronous processing for background operations. Neither pattern is forced where it doesn't fit.
Cloud-Agnostic: What It Actually Means
"Cloud-agnostic" is one of those phrases that gets thrown around loosely. Here's what it means in Matih's architecture, concretely:
Storage — Kubernetes PersistentVolumeClaims, not cloud storage APIs. The platform doesn't call Azure Blob or S3 directly in application code.
Secrets — Kubernetes Secrets with External Secrets Operator for vault integration. Whether your vault is Azure Key Vault, AWS Secrets Manager, or HashiCorp Vault, the application code doesn't change.
DNS — Abstracted through cert-manager and NGINX ingress controllers. The platform doesn't call Route53 or Azure DNS directly.
Identity — Workload identity patterns that map to Azure AD, AWS IAM, or GCP IAM via Kubernetes service accounts.
Infrastructure — Terraform modules for Azure, AWS, and GCP. Same platform. Different terraform apply.
The result: an organization can start on AKS, migrate to EKS, or run in a hybrid configuration — without changing application code. The same Helm charts deploy everywhere. The same cd-new.sh pipeline runs everywhere. The abstraction isn't theoretical. It's structural.
Developer Experience: The Fourth Plane
There's a hidden "plane" in the architecture that doesn't show up in diagrams: the developer experience.
Convention over configuration. Every service has a registered port in components.yaml — the single source of truth. Health endpoints follow a consistent pattern. API versioning follows /api/v1/ prefix convention. Event naming follows CATEGORY.ACTION patterns. Database naming matches service naming. An engineer who knows one service can navigate any service.
Scripts over tribal knowledge. 142 scripts, 61,000+ lines of shell code. Build a service? ./scripts/tools/service-build-deploy.sh ai-service. Check platform health? ./scripts/tools/platform-status.sh. Run the full CD pipeline? ./scripts/cd-new.sh all dev. If an operation requires more than one command, there's a script.
Observability as a compile-time dependency. You don't add logging after something breaks. Every service ships with structured JSON logging, Prometheus metrics, OpenTelemetry tracing, and deep health checks from day one. Observability is built in, not bolted on.
"The structure of the system reflects the structure of the organization that built it." — Conway's Law
Matih inverts this: the architecture was designed first, and the organizational structure follows the service boundaries. Each service is ownable by a small team. Each plane is independently deployable. Each namespace is independently securable.
What This Architecture Enables
The two-plane architecture isn't clever for the sake of cleverness. It enables specific capabilities that matter to real users:
Tenant isolation without tenant awareness. A business user asking questions about their data never thinks about multi-tenancy. But behind the scenes, their namespace, their database, their network policies, their resource quotas — everything is isolated. The architecture handles this structurally, not through application-level WHERE tenant_id = ? clauses (though those exist too, as defense in depth).
Independent scaling. The Control Plane stays lean — it manages metadata, not workloads. When a tenant's data grows 10x, only their Data Plane scales. When the platform adds 50 new tenants, only the Control Plane scales. Neither affects the other.
Zero-downtime platform upgrades. The Control Plane can be upgraded without interrupting running workloads. New Data Plane features can be rolled out to individual tenants without affecting others. The two-plane boundary is also an upgrade boundary.
Regulatory compliance by design. Customer data never leaves the Data Plane. The Control Plane handles only platform metadata. This means audit scoping, data residency, and access control can be enforced at the architectural level, not just the policy level.
The Road From Here
This post covered the structural "how" — two planes, 24 services, seven namespaces, and the design philosophy that holds it all together. But architecture without intelligence is just plumbing.
In the next two posts, we go deeper into what makes Matih think:
- Blog 3: Your Data Has Meaning — How ontologies and semantic queries turn "dumb SQL" into business intelligence that actually understands your business
- Blog 4: The Context Graph — The knowledge graph that gives the platform memory, context, and the ability to connect dots across your entire data landscape
About Matih: Matih is a cloud-agnostic, Kubernetes-native platform that unifies Data Engineering, Machine Learning, Artificial Intelligence, and Business Intelligence into a single system with a conversational interface at its core. Learn more at matih.ai (opens in a new tab).
Tags: #Architecture #Microservices #Kubernetes #CloudNative #DataPlatform #TwoPlane #Enterprise #SystemDesign
Previous: Intent to Insights: Why Your Data Stack Needs a Conversational Brain Next: Your Data Has Meaning: Ontologies, Semantic Queries, and the Death of Dumb SQL