Your Data Has Meaning: Ontologies, Semantic Queries, and the Death of Dumb SQL
"The limits of my language mean the limits of my world." — Ludwig Wittgenstein
Reading time: 14 minutes Series: The Matih Platform Blog Series (3 of 8) — Semantic Intelligence, Part 1 Audience: Data Engineers, Analysts, AI/ML Practitioners, Anyone who's ever written a JOIN wrong

The $4 Trillion Miscommunication
Here's a number that should make every CEO nervous: the average enterprise has 2,000+ database tables. Those tables have 50,000+ columns. And across those columns, there are approximately zero consistent definitions of what "revenue" means.
Sales says revenue is gross bookings. Finance says it's net of returns. Product says it's ARR. The CEO's dashboard uses a number that nobody can trace to a specific query because the analyst who built it left nine months ago.
This isn't a technology problem. It's a language problem. The data exists. The compute power exists. What doesn't exist is a shared vocabulary — a way for the organization to agree on what its words actually mean when translated into queries.
SQL doesn't solve this. SQL is a tool for talking to databases. It has no concept of business meaning. SELECT SUM(amount) FROM orders is syntactically perfect and semantically useless — because "amount" could mean list price, discounted price, or revenue-recognized price depending on which table you're looking at.
This is why Matih doesn't start with SQL. It starts with meaning.
What Is an Ontology (and Why Should You Care)?
The word "ontology" comes from philosophy — it's the study of what exists. In data platforms, an ontology is something far more practical: a formal description of the concepts in your business domain and the relationships between them.
Think of it as the difference between a phone book and a social network. A phone book lists names and numbers. A social network knows that Alice is Bob's manager, Bob works in the Portland office, the Portland office handles West Coast accounts, and West Coast accounts have a 15% higher churn rate in Q4.
An ontology captures all of that: entities (Customer, Order, Product, Region), their properties (name, email, tier, amount), their relationships (Customer places Order, Order contains Product, Product belongs to Category), and their constraints (email must be valid, amount must be positive, tier must be one of 'free', 'starter', 'professional', 'enterprise').
The Four Layers
Matih organizes ontologies into four layers, from raw source data up to business-ready meaning:
| Layer | What It Contains | Example |
|---|---|---|
| Raw | Unprocessed source data, as-is | CSV imports, API responses, raw logs |
| Staging | Cleaned, validated, deduplicated | Type-cast records, null-handling applied |
| Curated | Enriched, joined, business-ready | Customer 360 views, enriched transactions |
| Semantic | Domain model entities | "Premium Customer" = customers WHERE lifetime_value > $10K AND tenure > 2 years |
Most data platforms stop at the staging layer. They give you clean data and wish you luck figuring out what it means. Matih goes all the way to the semantic layer — where data has business meaning baked in.
The Semantic Layer: Where Business Logic Lives
Here's the core insight that most data platforms miss: business logic doesn't belong in dashboards. It doesn't belong in SQL queries. It belongs in a semantic layer that everyone shares.
When a VP asks "What's our revenue by region?", the answer shouldn't depend on which analyst writes the query. Revenue should be defined once, in a single place, and every query, dashboard, and AI-generated analysis should use that same definition.
Matih's semantic layer does exactly this through a Modeling Definition Language (MDL). It's a declarative specification of your business metrics, dimensions, and the relationships between them:
Metrics — Calculated business measures with precise definitions:
- "Total Revenue" =
SUM(orders.amount)on theordersfact table - "Average Order Value" =
AVG(orders.amount) - "Customer Churn Rate" =
COUNT(churned) / COUNT(total)— semi-additive, not summable across time
Dimensions — The axes along which you slice metrics:
- Region (categorical, with hierarchy: Country > Region > City)
- Date (temporal, with hierarchy: Year > Quarter > Month > Day)
- Product Category (categorical)
Relationships — How tables connect:
- Orders
MANY_TO_ONECustomers (viacustomer_id) - Customers
MANY_TO_ONERegions (viaregion_id) - Orders
MANY_TO_ONEProducts (viaproduct_id)
When someone asks "Show me total revenue by region for last quarter," the semantic layer knows exactly what that means:
Business Query: "total revenue by region for last quarter"
Semantic Resolution:
Metric: total_revenue → SUM(orders.amount)
Dimension: region → regions.region_name
Join Path: orders → customers → regions (auto-discovered)
Time Filter: orders.order_date >= '2025-10-01'
Generated SQL:
SELECT r.region_name, SUM(o.amount) AS total_revenue
FROM analytics.sales.orders o
JOIN analytics.crm.customers c ON o.customer_id = c.id
JOIN analytics.geography.regions r ON c.region_id = r.id
WHERE o.order_date >= DATE '2025-10-01'
AND o.order_date < DATE '2026-01-01'
GROUP BY r.region_name
ORDER BY total_revenue DESCNo ambiguity. No analyst interpretation. No "which revenue number is this?" conversations. The definition is the definition. Period.
The Catalog: Your Data's Living Map
The semantic layer defines what your business terms mean. But it needs a foundation — an accurate, up-to-date map of what data actually exists. That's the data catalog.
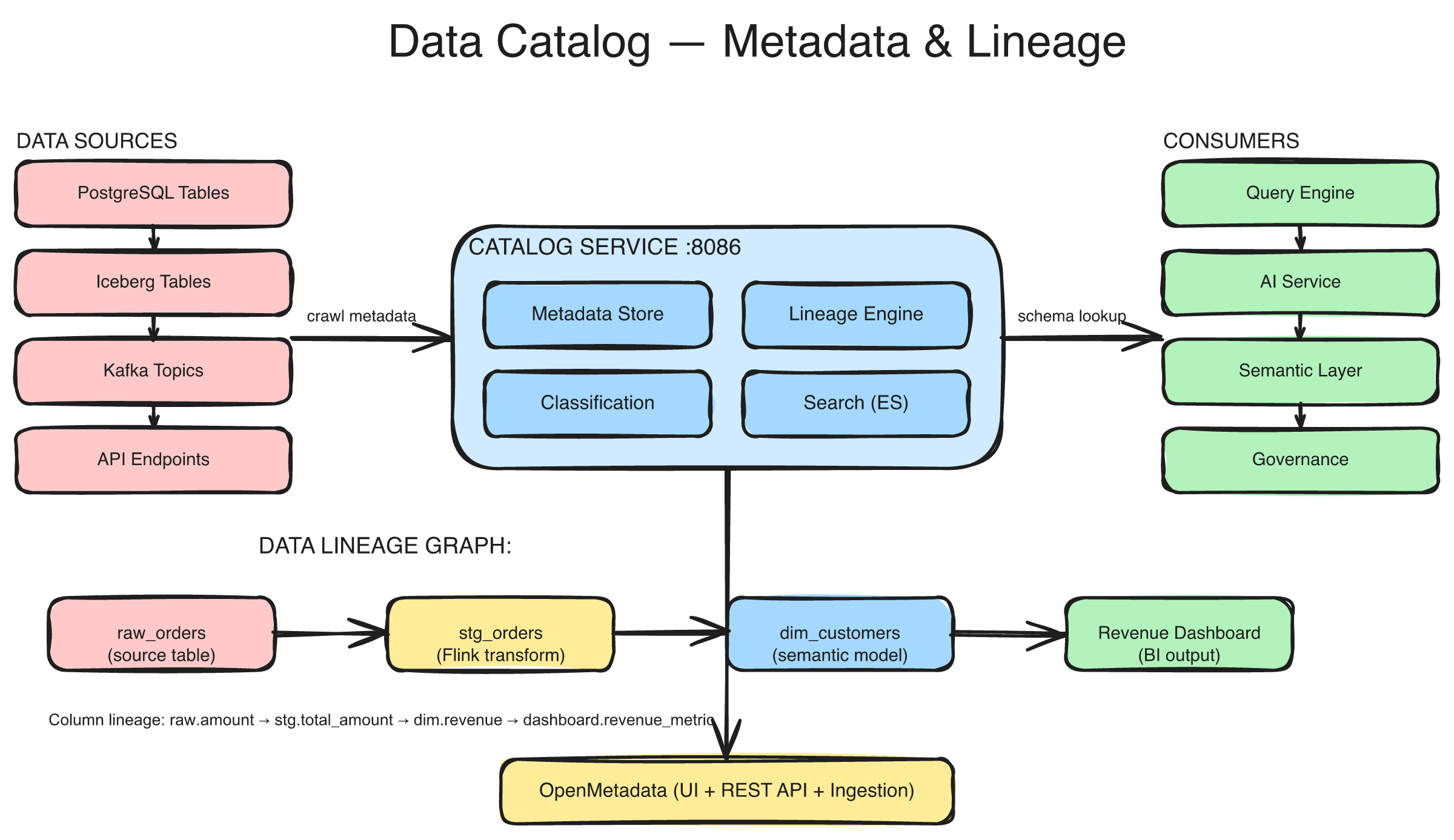
The catalog connects data sources (PostgreSQL, Iceberg, Kafka, APIs) to consumers (Query Engine, AI Service, Semantic Layer, Governance) through a central metadata store with lineage tracking, classification, and full-text search.
Matih's catalog automatically:
- Discovers schemas — Crawls connected data sources to find tables, columns, and types
- Tracks lineage — Knows that
stg_orderscomes fromraw_ordersvia a Flink transformation, and thatdim_customersfeeds the Revenue Dashboard - Classifies data — Detects PII (emails, phone numbers, SSNs) and applies sensitivity labels (PUBLIC, INTERNAL, CONFIDENTIAL, RESTRICTED)
- Monitors quality — Computes quality scores per table and per column, surfaces anomalies
- Enables search — Full-text search across all cataloged assets via Elasticsearch
The catalog is what makes the semantic layer trustworthy. Without it, your metric definitions point to tables that may have changed, columns that may have been renamed, or data that may have degraded in quality. With it, every semantic query is grounded in verified, current reality.
Ontology-Guided RAG: The Secret Weapon
Here's where things get genuinely exciting.
Traditional AI-powered analytics tools use schema-based RAG — they embed table and column descriptions into a vector store, then retrieve the most similar schemas when generating SQL. This works... okay. It gets you maybe 88% accuracy on well-structured databases.
Matih uses Ontology-Guided RAG (OG-RAG) — a fundamentally different approach that uses the ontology as the retrieval context instead of raw schemas. The difference in accuracy is dramatic.
How OG-RAG Works
User: "What is the total value of premium customer orders?"
Step 1 — Concept Extraction:
Concepts identified: [premium_customer, order_value]
Step 2 — Ontology Lookup:
premium_customer → Customer entity WHERE tier = 'premium'
order_value → Order entity, property: total_amount
Step 3 — Relationship Resolution:
Customer PLACES Order (one-to-many)
Join path: orders.customer_id = customers.id
Step 4 — SQL Generation (with ontology context):
SELECT SUM(o.total_amount) AS total_value
FROM orders o
JOIN customers c ON o.customer_id = c.id
WHERE c.tier = 'premium'
Step 5 — SHACL Validation:
✓ tier is a valid property of Customer
✓ 'premium' is a valid enum value for tier
✓ total_amount is a numeric property of Order
Confidence: 0.91The key difference: OG-RAG doesn't just match words to columns. It understands concepts. "Premium customer" isn't a table or a column — it's a business concept that maps to a filtered entity. Schema-based RAG would struggle with this. OG-RAG resolves it naturally because the ontology already defines what "premium customer" means.
SHACL: The Guardrail
Every query generated through OG-RAG passes through SHACL validation (Shapes Constraint Language) — a W3C standard for validating data against structural constraints. SHACL catches errors that SQL validation alone would miss:
- Is "tier" actually a property of Customer? (Not just a column that happens to exist somewhere)
- Is "premium" a valid value for that property? (Not a typo or an outdated category)
- Is the join path semantically valid? (Customers place Orders, but do Orders belong to Regions? Only through Customers.)
SHACL validation happens before the query hits the database. Bad queries die early, with clear error messages, rather than returning wrong results silently.
10 Industries, Ready to Go
Building an ontology from scratch is hard work. That's why Matih ships with 10 pre-built industry ontology templates, each with domain-specific entities, relationships, properties, governance metadata, and validation rules:
| Template | Key Entities | Use Case |
|---|---|---|
| E-Commerce | Customer, Order, Product, Category, Review | Retail analytics, conversion funnels |
| Financial Services | Account, Transaction, Customer, Portfolio | Banking, wealth management |
| Healthcare | Patient, Encounter, Diagnosis, Medication | Clinical analytics, population health |
| Manufacturing | Product, WorkOrder, Machine, Inventory | Operations, predictive maintenance |
| SaaS | User, Subscription, Invoice, Feature | Subscription metrics, churn analysis |
| Supply Chain | Supplier, PurchaseOrder, Shipment, Warehouse | Logistics, procurement optimization |
| Marketing | Campaign, Lead, Contact, Conversion | Attribution, funnel analytics |
| IoT | Device, Sensor, Reading, Alert | Telemetry, anomaly detection |
| HR | Employee, Department, Position, Performance | People analytics, workforce planning |
| Education | Student, Course, Enrollment, Grade | Academic analytics, retention |
Each template comes with PII field markings (email = CONFIDENTIAL), governance metadata (owner, steward, retention policy), relationship cardinalities, and pre-configured validation rules. Deploy a template, customize it for your domain, and you have a production-ready ontology in minutes instead of months.
The Three-Layer Intelligence Stack
Here's how all of this fits together — three services working in concert to turn business language into precise, validated, trustworthy SQL:
┌─────────────────────────────────────────────────────┐
│ SEMANTIC LAYER │
│ "Revenue = SUM(orders.amount)" │
│ "Region = regions.region_name via customers" │
│ Business metrics, dimensions, join paths │
└─────────────────┬───────────────────────────────────┘
│
┌─────────────────▼───────────────────────────────────┐
│ ONTOLOGY SERVICE │
│ "Customer has tier ∈ {free, starter, premium}" │
│ "Order MANY_TO_ONE Customer via customer_id" │
│ Entity types, properties, relationships, SHACL │
└─────────────────┬───────────────────────────────────┘
│
┌─────────────────▼───────────────────────────────────┐
│ DATA CATALOG │
│ "analytics.sales.orders has 12M rows, quality: 97%"│
│ "Column 'email' is PII, classification: CONFIDENTIAL│
│ Physical tables, lineage, quality scores, search │
└─────────────────────────────────────────────────────┘The catalog tells you what data exists and where it lives. The ontology tells you what that data means and how it connects. The semantic layer tells you how to measure and analyze it.
When the AI generates SQL, it draws from all three layers. The result isn't a guess based on column name similarity — it's a precise, semantically grounded, ontology-validated query that uses the organization's own definitions.
"Data is not information, information is not knowledge, knowledge is not understanding, understanding is not wisdom." — Clifford Stoll
The catalog gives you data. The ontology gives you knowledge. The semantic layer gives you understanding. The conversational AI gives you wisdom — or at least, actionable insights.
Why "Dumb SQL" Is Leaving Money on the Table
Let's be blunt about what happens without this stack:
Without a semantic layer: Every analyst defines "revenue" differently. Dashboard A shows 3.8M, and nobody knows which is right. The executive team loses trust in all data.
Without an ontology: The AI generates SQL by matching words to column names. "Premium customers" becomes WHERE column_name LIKE '%premium%' — which might find the right column, or might match premium_shipping_flag instead. Wrong query. Wrong answer. Zero confidence.
Without a catalog: The AI doesn't know that the orders table was deprecated last month and replaced with orders_v2. It generates a query against stale data. The answer is technically correct and practically useless.
With all three: The query is semantically precise (ontology), uses the correct business definitions (semantic layer), and targets current, quality-verified data (catalog). The answer isn't just right — it's trustworthy. And trust is what turns data from a cost center into a competitive advantage.
What This Means for Your Organization
If you're a data engineer, this means less time writing and maintaining SQL transformations, and more time designing the ontology that makes all downstream queries accurate. Your work becomes a force multiplier instead of a bottleneck.
If you're a business analyst, this means asking questions in your own language and getting answers that use your organization's agreed-upon definitions. No more SQL. No more "which dashboard is right?" conversations.
If you're a data scientist, this means your feature engineering starts from semantically clean, ontology-defined entities rather than raw tables with cryptic column names. Your models train on meaning, not noise.
If you're a platform engineer, this means the catalog and ontology are versioned, validated, and governed — not a wiki page that nobody updates.
Coming Up Next
This post covered the "what" and "why" of semantic intelligence — ontologies, the semantic layer, the catalog, and how they work together. In the next post, we go deeper into the Context Graph: the knowledge graph that gives Matih memory, pattern recognition, and the ability to connect dots that no human could connect alone.
- Blog 4: The Context Graph: Your Organization's Memory That Never Forgets — GraphRAG, temporal memory, causal analysis, and how relationships between data assets create intelligence
About Matih: Matih is a cloud-agnostic, Kubernetes-native platform that unifies Data Engineering, Machine Learning, Artificial Intelligence, and Business Intelligence into a single system with a conversational interface at its core. Learn more at matih.ai (opens in a new tab).
Tags: #Ontology #SemanticLayer #DataCatalog #DataEngineering #AI #TextToSQL #DataGovernance #Analytics
Previous: The Architecture of Understanding Next: The Context Graph: Your Organization's Memory That Never Forgets