From Bytes to Brilliance: Data Processing at Planetary Scale
"It is a capital mistake to theorize before one has data." — Arthur Conan Doyle
Reading time: 14 minutes Series: The Matih Platform Blog Series (6 of 8) Audience: Data Engineers, Platform Engineers, Anyone who's ever waited for a query to finish

The Four-Letter Word That Runs Your Business
Every data platform makes the same promise: we'll process your data. Fast. At scale. No problem.
Then reality shows up.
Your payment processing pipeline needs to handle 10,000 transactions per second with 100ms latency — that's a streaming problem. Your quarterly financial reconciliation needs to join 500 million records across three data warehouses — that's a batch problem. Your CEO wants a dashboard that pulls real-time metrics from Kafka, historical trends from the data lake, and customer data from PostgreSQL — all in one query. That's a federation problem.
No single engine solves all three. Spark is brilliant at batch but adds seconds of latency to streaming. Flink is brilliant at streaming but overkill for scheduled ETL. Trino can federate across sources but can't run your machine learning feature pipeline.
Most platforms pick one engine and force everything through it. The result: you're either over-engineering simple jobs or under-serving complex ones.
Matih picked a different approach: four engines, one API, zero compromise.
The Unified Pipeline Service
At the heart of Matih's data processing layer is the Pipeline Service — a single orchestration layer that abstracts four distinct execution engines behind one REST API:
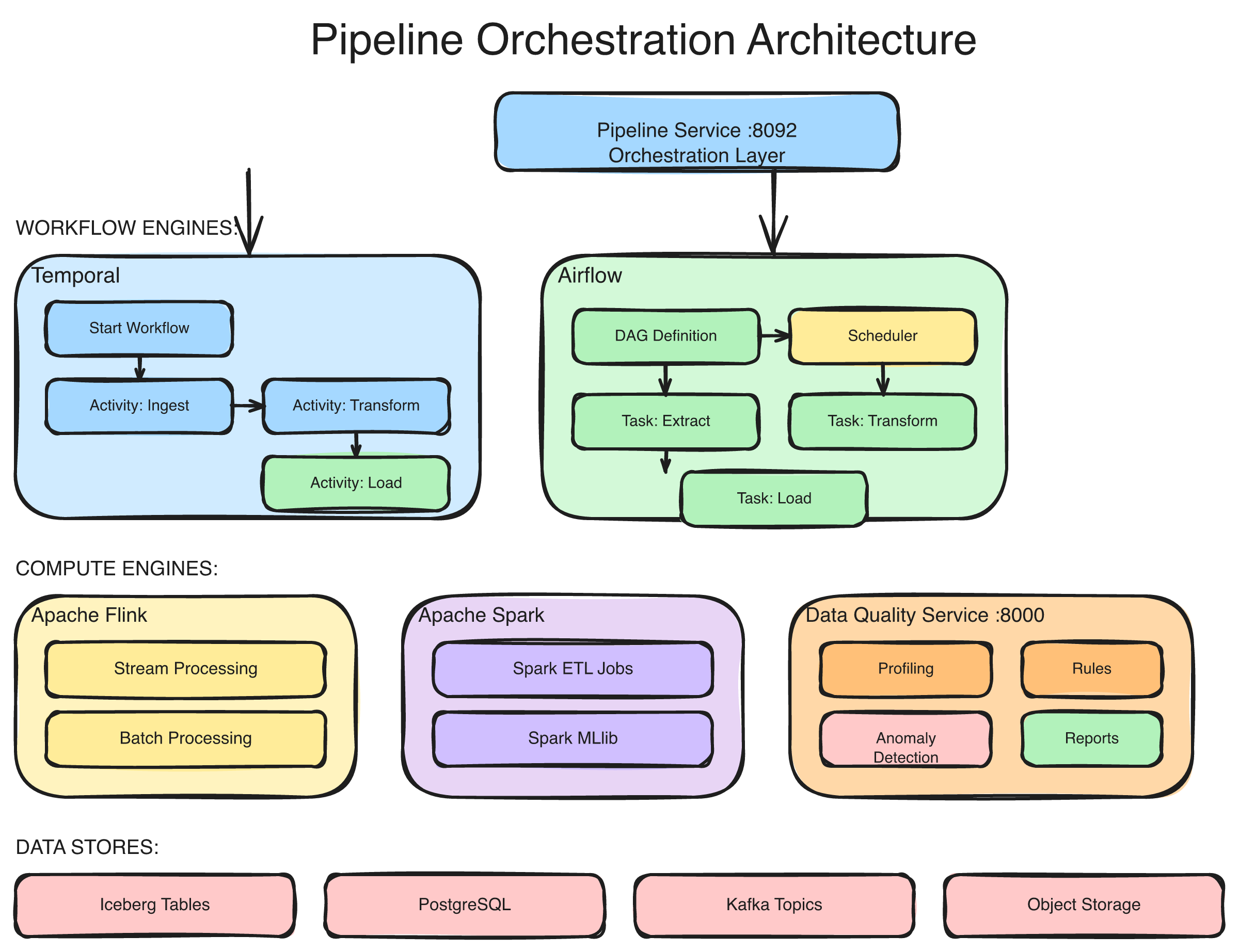
The Pipeline Service routes workloads to the optimal engine: Airflow for scheduled DAG orchestration, Spark for large-scale batch transformations, Flink for real-time streaming and CDC, and Temporal for long-running stateful workflows. All engines share a common API, monitoring layer, and tenant isolation model.
Airflow — The Scheduler
Best for: Scheduled batch jobs, DAG-based orchestration, dependency management.
Airflow is the workhorse for anything that runs on a schedule — nightly data loads, hourly aggregations, weekly reports. It manages task dependencies (load data then transform then publish), handles retries on failure, and provides visibility into what ran, what failed, and why.
In Matih, each tenant gets isolated Airflow resources — your DAGs don't compete with another tenant's jobs for scheduler slots.
Spark — The Heavy Lifter
Best for: Large-scale transformations, joins across massive datasets, ML feature engineering.
When you need to join 500 million rows, compute window functions across a year of transaction data, or run a distributed ML training job, Spark is the engine that scales. Matih's Spark integration supports multiple deployment modes — Kubernetes-native submission, YARN clusters, and managed cloud services (Databricks, EMR, Dataproc) — with dynamic resource allocation that scales from 1 to 32 executors based on workload.
Output goes wherever you need it: Parquet, Delta Lake, Apache Iceberg, ORC, or Avro — with configurable partitioning, compression, and merge strategies.
Flink — The Speed Demon
Best for: Real-time streaming, Change Data Capture (CDC), sub-second latency requirements.
Flink processes data as it arrives — not in batches, not on schedules, but continuously. When a payment transaction hits Kafka, Flink picks it up, enriches it with merchant data, scores it for fraud risk, applies business rules, and publishes the result — all within 100 milliseconds.
Matih deploys Flink via Kubernetes operators with built-in checkpointing for fault tolerance. If a Flink job fails, it resumes from the last checkpoint — no data loss, no reprocessing from scratch.
Temporal — The Long Runner
Best for: Complex stateful workflows, multi-step processes with retry logic, human-in-the-loop pipelines.
Some workflows don't fit neatly into "batch" or "stream." A data pipeline that needs to call an external API, wait for a callback, retry with exponential backoff on failure, and escalate to a human after three failures — that's a Temporal workflow.
Temporal provides durable execution: workflow state survives process restarts, infrastructure failures, and even cluster migrations. It's the engine behind Matih's most complex orchestration patterns, including tenant provisioning, cross-system reconciliation, and approval-gated data transformations.
One API to Rule Them All
Here's what the developer experience looks like. You don't choose an engine — you describe what you need, and the Pipeline Service routes to the right one:
Create Pipeline:
Source: Kafka topic "raw_transactions" (streaming)
Transform: Enrich with merchant data, score fraud risk, apply rules
Sink: Delta Lake "processed_transactions" + Kafka "settled_txns"
Latency: < 100ms
Volume: 10,000 events/second
Pipeline Service Resolution:
Engine: Flink (streaming requirement + low latency)
Deployment: FlinkDeployment on Kubernetes
Checkpoint: Incremental, every 60 seconds
Resources: 2 TaskManagers, 4GB eachOr a batch job:
Create Pipeline:
Source: PostgreSQL "orders" table (incremental, since last sync)
Transform: Join with customers, compute lifetime value, classify tier
Sink: Iceberg "customer_360"
Schedule: Daily at 2:00 AM UTC
Pipeline Service Resolution:
Engine: Spark (large dataset + complex joins)
Deployment: Kubernetes, 4 executors, dynamic allocation
Format: Iceberg (Copy-on-Write, partitioned by date)The Pipeline Service handles scheduling, monitoring, retry logic, error handling, and resource management. You describe the what. The platform handles the how.
The Query Engine: Asking Questions Across Everything
Processing data is half the story. The other half is querying it — and in a modern organization, "the data" lives in five different places.
Matih's Query Engine federates queries across multiple data sources, routes to the optimal execution backend, and caches aggressively at three levels:
Intelligent Query Routing
Not all queries are created equal. A simple SELECT COUNT(*) GROUP BY region on pre-aggregated data should return in milliseconds, not seconds. A complex 12-table join across a data lake and a warehouse genuinely needs 30 seconds.
The Query Engine's compute-aware router analyzes each query and sends it to the fastest capable backend:
| Query Pattern | Routed To | Why | Typical Latency |
|---|---|---|---|
| Simple aggregations, no joins | ClickHouse | Columnar OLAP, pre-aggregated | < 1 second |
| Complex multi-table joins | Trino | Cost-based optimizer, federation | 1–30 seconds |
| Small dataset analytics | DuckDB | In-process, zero overhead | < 500ms |
| Cross-source federation | Trino | Connector ecosystem | 5–60 seconds |
The routing is transparent. Users and AI agents don't know (or need to know) which backend executed their query. They just see fast results.
Three-Level Caching
Every query passes through a three-level cache before hitting the database:
Level 1 — In-Memory (Caffeine): Local to each Query Engine pod. Sub-millisecond lookups. Holds the most frequently accessed results. 500MB per pod, 5-minute access expiry.
Level 2 — Distributed (Redis): Shared across all Query Engine replicas. Compressed storage for large result sets. Entries linked to source table metadata for smart invalidation — when a table updates, all queries that depend on it are automatically invalidated.
Level 3 — Materialized Views: For queries that run hundreds of times per day (dashboard widgets, recurring reports), the system can create materialized views that pre-compute results. The Context Graph identifies these candidates automatically by tracking query frequency.
The result: dashboard loads in under 2 seconds, even when the underlying data spans multiple sources and billions of rows.
Federation: One Query, Five Sources
Here's the query that traditional platforms can't run:
SELECT
c.customer_name,
o.total_orders,
s.support_tickets,
m.churn_probability
FROM warehouse.customers c
JOIN lakehouse.order_aggregates o ON c.id = o.customer_id
JOIN postgres.support.tickets s ON c.id = s.customer_id
JOIN mlflow.predictions m ON c.id = m.customer_id
WHERE m.churn_probability > 0.7
ORDER BY m.churn_probability DESCFour data sources. One query. The data warehouse holds customer profiles. The data lake holds order aggregates. PostgreSQL holds support tickets. The ML model registry holds churn predictions. Trino federates across all four, joins the results, and returns them as a single result set.
No ETL pipeline needed to consolidate the data first. No copy-paste between systems. The data stays where it lives, and the query goes to the data.
Data Ingestion: Getting Data In
Before you can process or query data, you need to get it into the platform. Matih supports four ingestion patterns, each optimized for different scenarios:
Full Load — Complete table replacement. Best for small reference tables (product catalogs, region lookups) where incremental tracking isn't worth the complexity.
Incremental Sync — Only fetch what changed since the last sync. Supports timestamp-based detection (WHERE updated_at > last_sync), version-based tracking, and checksum comparison. This is the default for most operational data — it reduces transfer volume by 90%+ compared to full loads.
Change Data Capture (CDC) — Capture inserts, updates, and deletes directly from database transaction logs. Zero impact on the source database. Supports PostgreSQL WAL, MySQL binlog, Oracle LogMiner, and SQL Server CDC. This is how you get near-real-time data freshness without hammering your production database with queries.
Streaming Ingestion — Direct consumption from message brokers (Kafka, Kinesis). For data that's already flowing through event streams — clickstreams, IoT telemetry, transaction events — this provides the lowest latency path into the platform.
Each pattern supports parallel extraction (up to 32 concurrent streams), configurable batch sizes, schema evolution handling, and automatic conflict resolution for upserts.
Data Quality: Trust Built Into the Pipeline
Processing data without checking its quality is like building a house without inspecting the foundation. Matih integrates quality checks directly into the pipeline:
Six quality dimensions measured continuously:
- Completeness — What percentage of expected values are present? A column with 30% nulls gets flagged.
- Accuracy — Do values pass domain validation rules? Negative transaction amounts, future birth dates, invalid currency codes — all caught automatically.
- Consistency — Do related tables agree? If the orders table shows 1,000 orders for Customer X, does the customer table confirm Customer X exists?
- Timeliness — How fresh is the data? If the SLA says "data within 5 minutes of real-time" and the last update was 30 minutes ago, that's a breach.
- Uniqueness — Are there duplicates? Transaction IDs should be unique within a 24-hour window.
- Validity — Do values conform to expected formats? Email addresses, phone numbers, postal codes — each with its own validation pattern.
Quality scores travel with the data. When an AI agent generates a query, the result includes a confidence indicator based on the quality scores of the underlying tables. "Revenue for Q4 is 4.2M (data quality: 68% — 3 source tables have freshness issues)" tells you to investigate before making decisions.
Industry Pipeline Templates
Building pipelines from scratch is expensive and error-prone. Matih ships with 12+ pre-built pipeline templates for common industry patterns:
| Industry | Pipeline | Scale | Latency |
|---|---|---|---|
| Fintech | Payment processing, fraud scoring, settlement | 50M txns/day | 100ms |
| E-Commerce | Inventory sync, recommendation engine, cart analytics | 1M SKUs | 5 min |
| AdTech | Real-time bidding, impression tracking, attribution | Millions/hour | < 50ms |
| Healthcare | Patient records, clinical trial data, compliance | TB-scale | Daily |
| IoT/Energy | Meter data collection, sensor aggregation, alerting | 100M devices | 15 min |
| Cybersecurity | Threat detection, log analysis, anomaly scoring | 1B events/day | < 1 min |
Each template includes pre-configured source connectors, transformation logic, quality checks, alerting rules, and monitoring dashboards. Deploy a template, point it at your data sources, customize the business rules, and you have a production pipeline in hours instead of months.
Scaling: From Startup to Enterprise
The four-engine architecture scales naturally because each engine scales independently:
Vertical scaling — Need more power for a Spark job? Increase executor memory from 2GB to 16GB. Need faster Flink processing? Add more TaskManager replicas. The Pipeline Service adjusts resources per job, not per cluster.
Horizontal scaling — As query volume grows, add Query Engine replicas behind a load balancer. Each replica has its own L1 cache but shares L2 (Redis) for consistency. The cache hit rate improves as more queries warm the distributed cache.
Tenant isolation — Each tenant's workloads run in isolated Kubernetes namespaces with dedicated resource quotas. One tenant's runaway Spark job can't consume another tenant's CPU allocation. Resource limits are enforced at the infrastructure level, not the application level.
Tiered governance — Query limits scale with the subscription tier: concurrent query limits, row limits, and timeout thresholds ensure fair resource distribution without manual intervention.
How It All Connects
The data processing layer doesn't exist in isolation. It's deeply integrated with every other layer of the platform:
Semantic Layer → Query Engine: When an AI agent translates "Show me revenue by region" into SQL, the semantic layer provides the metric definition and the Query Engine executes it — routing to the fastest backend, caching the result, and tracking the query in the Context Graph.
Pipeline Service → Data Catalog: Every pipeline execution updates the catalog with lineage metadata — what data was read, what was written, what transformations were applied. This is how impact analysis knows that changing a source table affects downstream dashboards.
Data Quality → AI Service: Quality scores feed directly into the AI agent's confidence scoring. The agent won't present results from a table with a 60% quality score without flagging it. Trust is computed, not assumed.
Context Graph → Cache Warming: The Context Graph tracks which queries run most frequently. The cache warming system uses this to pre-compute results for high-traffic queries before users ask for them.
"Data is the new oil. But like oil, it's valuable only when refined." — Clive Humby
Matih's processing layer is the refinery — four engines working in concert to turn raw data into queryable, quality-verified, semantically meaningful assets that the entire platform can build on.
What This Means for Your Organization
If you're a data engineer, this means you describe pipelines, not infrastructure. One API for batch, streaming, CDC, and stateful workflows. Templates for common patterns. Quality checks built in, not bolted on.
If you're a platform engineer, this means four engines running on Kubernetes with per-tenant isolation, autoscaling, and unified monitoring — without maintaining four separate clusters.
If you're a business analyst, this means your queries run fast regardless of where the data lives. Federation, caching, and intelligent routing are invisible — you just see results.
If you're an executive, this means data freshness measured in seconds for streaming workloads and minutes for batch — not days. Decisions made on current data, not stale snapshots.
Coming Up Next
This post covered how Matih processes and queries data at scale. Next, we tackle the enterprise concerns that keep CISOs up at night — security, governance, multi-tenancy, and compliance.
- Blog 7: Enterprise-Grade Without Enterprise Pain: Security, Governance, and Trust — Multi-tenant isolation, row-level security, data classification, audit trails, and why compliance shouldn't require a dedicated team
About Matih: Matih is a cloud-agnostic, Kubernetes-native platform that unifies Data Engineering, Machine Learning, Artificial Intelligence, and Business Intelligence into a single system with a conversational interface at its core. Learn more at matih.ai (opens in a new tab).
Tags: #DataProcessing #Streaming #BatchProcessing #Flink #Spark #Trino #QueryFederation #DataEngineering #Pipeline
Previous: Forward Deployed AI Agents: The Engineers That Never Sleep Next: Enterprise-Grade Without Enterprise Pain: Security, Governance, and Trust