34 Microservices, 960 Docs Pages, 1 AI Pair Programmer: Building Matih with Claude Code
"First, solve the problem. Then, write the code." — John Johnson
Reading time: 15 minutes Series: The Matih Platform Blog Series (8 of 8) Audience: Developers, AI Enthusiasts, Technical Leaders, Anyone curious about AI-assisted development at scale

The Experiment Nobody Predicted
What happens when you try to build an enterprise data platform — 25 microservices, 76 Helm charts, 960 documentation pages — with an AI coding partner?
That's not a thought experiment. It's what we did.
Matih started as an ambitious idea: a unified platform that brings together Data Engineering, Machine Learning, Artificial Intelligence, and Business Intelligence under a single conversational interface. The kind of platform that would typically require a team of 30-50 engineers working for 2-3 years.
Instead, we built it with a small team and Claude Code — Anthropic's AI coding assistant — as a full-time pair programming partner. Not for toy projects or prototypes. For production-grade enterprise software with multi-tenancy, security, compliance, and the kind of infrastructure that CISOs actually sign off on.
Here's what we learned.
The Numbers
Let's start with what was built, because the scale is part of the story:
| Dimension | Count |
|---|---|
| Microservices | 25 (10 control plane + 15 data plane) |
| Frontend workbenches | 8 React applications |
| Commons libraries | 4 shared modules (Java, Python, TypeScript, AI) |
| Helm charts | 76 (services + infrastructure) |
| Shell scripts | 143 scripts, 62,000+ lines |
| Documentation pages | 960+ across 20 chapters |
| Lines of code | 1.8M+ (Java, Python, TypeScript, Shell, YAML) |
| Source connectors | 42+ (databases, APIs, SaaS, files) |
| Industry templates | 12+ pipeline templates, 10 ontology templates |
| Git commits | 845+ |
Three programming languages. Four execution engines. Seven Kubernetes namespaces. And a documentation site comprehensive enough that a new engineer can understand the entire platform without asking a single question.
This wasn't built by throwing code at a wall. It was built systematically — with an AI partner that gets better every time you teach it something new.
How AI Pair Programming Actually Works (Not the Marketing Version)
Let's dispense with the hype. AI pair programming is not "describe your app and watch it appear." It's not magic. It's not replacing engineers. Here's what it actually is:
It's a force multiplier for experienced engineers. You still need to know what you're building, why you're building it, and how it should work. The AI accelerates the translation from intent to implementation — but only if you can provide clear intent and evaluate the implementation.
It's pattern execution at scale. Once you establish a pattern (how a Spring Boot service is structured, how a FastAPI service handles multi-tenancy, how a Helm chart should be organized), the AI can replicate that pattern across dozens of services with remarkable consistency. The 10th service looks like the 1st service, because the AI doesn't get bored, doesn't forget conventions, and doesn't take shortcuts.
It's a knowledge repository that participates in development. This is the part nobody talks about. The real value isn't the code generation — it's the knowledge accumulation. Every lesson learned, every debugging session, every architectural decision gets codified and applied to future work.
The CLAUDE.md: Teaching Your AI Partner
The single most important file in our entire repository isn't a service, a chart, or a script. It's .claude/CLAUDE.md — a living document that teaches Claude Code how to work in our codebase.
Think of it as onboarding documentation, but for an AI. It contains:
Rule Zero — The highest-priority instruction: "Understand Before You Fix." Before writing any fix, read the actual error, trace the data flow, read upstream source code, identify the root cause, then fix it. This single rule prevents the most expensive AI failure mode: confidently fixing the wrong thing.
Coding standards by language — How Java services are structured (controller → service → repository → entity). How Python services handle configuration (Pydantic BaseSettings). How React workbenches manage state (Zustand + TanStack Query). The AI follows these patterns because they're explicitly documented, not because it inferred them from examples.
Mandatory rules with historical lessons — This is where it gets interesting. Every time we hit a significant bug, we didn't just fix it — we added a rule to CLAUDE.md that prevents the entire category of bug from recurring. Each rule includes the lesson source (what actually went wrong), the rule itself, and a "STOP CHECK" that forces verification before proceeding.
Forbidden commands — Explicit lists of commands the AI should never run directly (kubectl, docker build, helm install) with the script alternatives it should use instead. This prevents the AI from taking shortcuts that bypass our standardized tooling.
Pre-action checklists — Before modifying a Helm chart: "Have I verified the Docker image exists? Have I verified the container UID/GID? Do I know the service's config model?" Before modifying a Python service: "Does every import statement have a corresponding entry in pyproject.toml?"
The result: an AI partner that doesn't just write code — it writes code that follows our conventions, avoids our known pitfalls, and uses our standardized tooling. Every time.
Lessons That Became Rules
Here are some of the real failures that became permanent rules in our development process — each one discovered through an actual production incident:
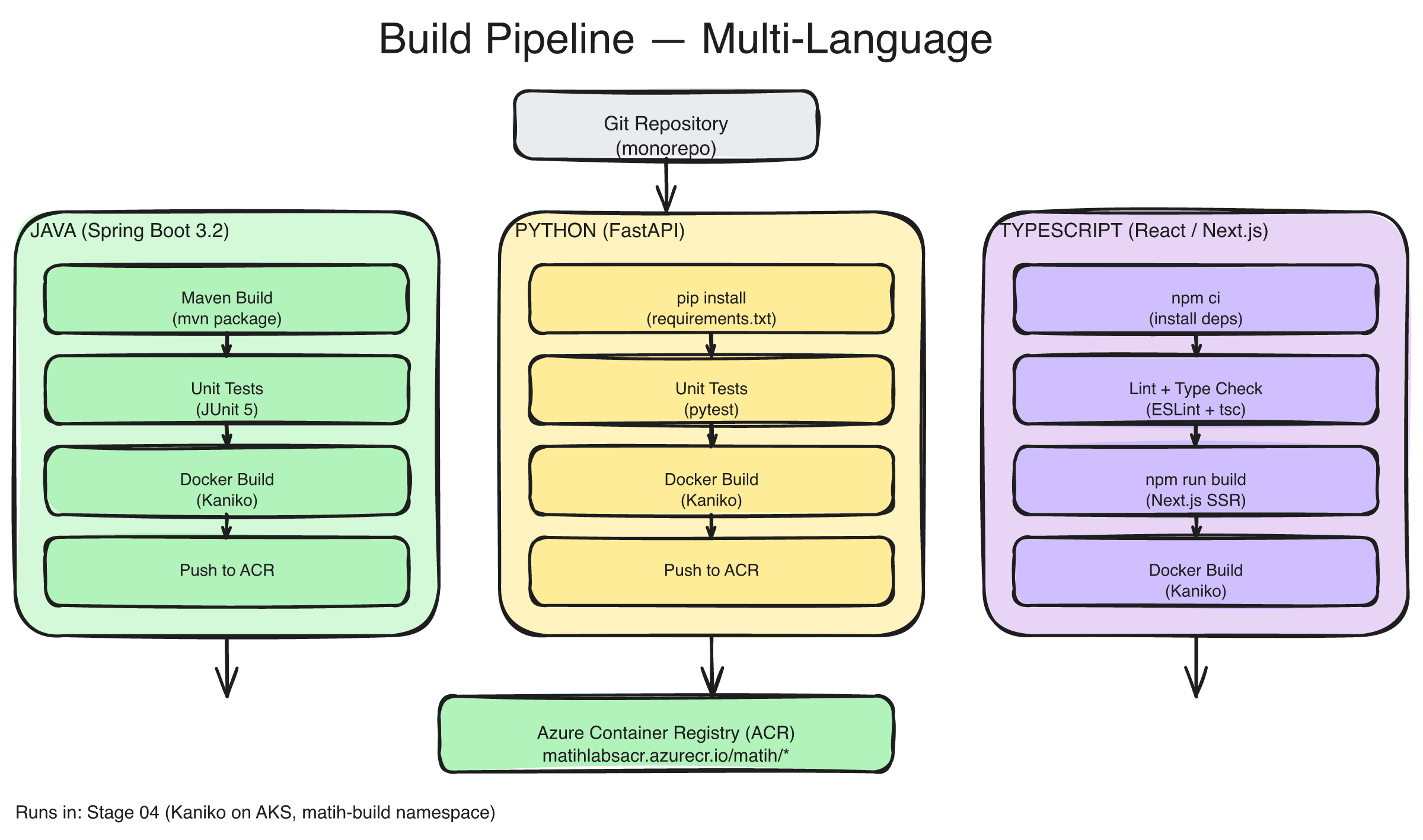
The build and deployment pipeline: source code flows through language-specific build stages (Java/Maven, Python/UV, TypeScript/Vite), Docker image creation with build-time validation, Helm chart rendering and linting, and Kubernetes deployment — with automated checks at every gate.
"The Silent Import Failure"
What happened: The data-quality-service deployed to Kubernetes and immediately crashed with ModuleNotFoundError: No module named 'yaml'. PyYAML was imported in the Python code but never declared in pyproject.toml. It worked locally because another package pulled it in transitively.
The rule: Every Python Dockerfile now includes a build-time import check — a line that imports the application's entry point at build time, catching missing dependencies before the image ships. The build fails loudly in CI instead of silently in production.
Why AI needed this rule: Without it, the AI would generate code that imports libraries and assumes they're available. The rule forces a verification step that catches the gap between "code references it" and "it's actually installed."
"The Wrong Database URL"
What happened: The data-quality-service deployed but couldn't connect to its database. The Helm chart injected separate DB_HOST, DB_PORT, DB_NAME environment variables, but the Pydantic config expected a single DATABASE_URL connection string. The service silently fell back to localhost:5432 and crashed.
The rule: Before writing Helm environment variables for any Python service, read settings.py first. Does it expect DATABASE_URL or separate components? The rule includes the exact YAML pattern to follow.
Why AI needed this rule: Different services use different configuration patterns. Without reading the actual settings file, the AI would guess — and guess wrong half the time.
"The Exhaustive Switch"
What happened: Adding a new enum value (PROVISION_DBT_ENVIRONMENT) to a Java enum broke the build — not in the obvious switch statement (which was updated), but in a second switch statement in the same file that nobody knew about. Java's exhaustive switch expressions fail to compile when a case is missing.
The rule: When adding a new value to any Java enum, search the entire codebase for all switch statements on that enum. Update every one.
Why AI needed this rule: AI tends to update the most obvious usage and move on. The rule forces comprehensive search before declaring the change complete.
"The Stale Helm Repo"
What happened: The Flink Operator Helm repo was cached with a stale URL pointing to version 1.10.0. The code referenced version 1.13.0, but helm repo add skipped the update because the repo name already existed. Result: 404 errors during deployment.
The rule: Every helm repo add command must include --force-update. Never skip repo adds based on name matching.
Why AI needed this rule: It's a subtle infrastructure behavior that even experienced engineers miss. Codifying it prevents recurrence.
The Knowledge Architecture
The .claude/ directory grew into something unexpected: a comprehensive knowledge architecture with 109 markdown files organized by purpose:
| Directory | Files | Purpose |
|---|---|---|
systems/ | 3 | Architecture, deployment, testing — the big picture |
modules/ | 8 | Per-service context — deep dives into each service |
skills/ | 44 | Task-specific instructions — "how to add a connector," "how to deploy" |
pool/patterns/ | 4 | Reusable code patterns — Spring Boot, FastAPI, React, multi-tenancy |
pool/snippets/ | 3 | Copy-paste code blocks — error handling, JWT auth, state stores |
rules/ | 2 | Infrastructure rules (22 rules), shell script standards |
integrations/ | 4 | Third-party integration guides — Trino, OpenMetadata, Ray, LangGraph |
prd/ | 8 | Product requirements and implementation plans |
research/ | 11 | Platform evolution research and strategic analysis |
This isn't documentation for humans (though humans can read it). It's executable context for the AI partner. When Claude Code needs to add a new API endpoint to a Spring Boot service, it reads the pattern file. When it needs to debug a Helm chart, it reads the infrastructure rules. When it needs to understand how multi-tenancy works, it reads the module context.
The key insight: the investment in documentation pays for itself through the AI. Every hour spent writing a clear pattern file saves ten hours of AI-generated code that follows the wrong pattern.
The Commons Libraries: Consistency at Scale
One of the hardest problems in a polyglot microservice architecture: how do you keep 25 services consistent without coupling them?
We solved it with four commons libraries — shared code that enforces behavior without dictating architecture:
commons-java — JWT validation, tenant context propagation, structured logging, circuit breakers, health checks, cache management. Every Java service inherits this. When you see TenantContext.getCurrentTenantId() in any service, it comes from commons.
commons-python — Tenant middleware, JWT decoding, structured logging (structlog), health check patterns. The Python equivalent of the Java commons.
commons-typescript — API client with auth interceptors, shared hooks, component library. Every React workbench starts from the same foundation.
commons-ai — LLM abstractions, prompt management, RAG utilities, agent framework. Shared across all AI/ML services.
The AI pair programming value: once a pattern is implemented in commons, the AI replicates it correctly across every service that uses it. No drift. No "well, this service does it slightly differently because a different person wrote it."
Scripts Over Tribal Knowledge
We wrote 143 shell scripts totaling 62,000+ lines of code. That might sound excessive. It's not.
Every repeatable operation in the platform is a script. Build a service? ./scripts/tools/service-build-deploy.sh ai-service. Check platform health? ./scripts/tools/platform-status.sh. Validate all port assignments? ./scripts/tools/validate-ports.sh. Run the full deployment pipeline? ./scripts/cd-new.sh all dev.
The principle: if an operation requires more than one command, it's a script. Scripts are version-controlled, tested, and documented. Ad-hoc commands are none of those things.
For AI pair programming, this means the AI never runs raw kubectl or helm commands. It uses the scripts. The scripts encode our operational knowledge — error handling, validation checks, rollback logic — so every deployment follows the same reliable process regardless of who (or what) triggers it.
Documentation as a Product
960+ documentation pages across 20 chapters. That's not a nice-to-have — it's a core product of the development process.
The documentation covers everything: quickstart guides for five different user journeys, API references for every service, architecture deep dives, compliance documentation (SOC 2, HIPAA), operational runbooks, and troubleshooting guides.
Why invest so heavily in documentation for a platform still in development? Three reasons:
-
It forces clarity. You can't document what you don't understand. Writing documentation for the semantic layer forced us to resolve ambiguities in how metrics, dimensions, and relationships interact. The documentation didn't describe the system — it helped design it.
-
It scales the team. A new contributor can understand the entire platform by reading the docs. They don't need to schedule six different knowledge transfer sessions with six different people.
-
It powers the AI. Claude Code reads the documentation to understand context. When it needs to implement a feature in the AI service, it reads the AI service module docs, the LangGraph integration guide, and the relevant API contracts. The documentation is both human-readable and AI-consumable.
What We Got Wrong
Honest account time. Not everything about AI pair programming is sunshine:
The AI is confidently wrong. Claude Code will generate a Helm chart value that looks plausible, references a CLI flag that sounds right, and configures a security context that seems reasonable — and all three can be wrong. The flag doesn't exist in this version. The security context uses the wrong UID. The value doesn't trace to any actual upstream configuration.
This is why Rule Zero exists: "Understand Before You Fix." And it's why our pre-action checklists require verification against actual source code, not AI-generated assumptions. Trust but verify isn't optional — it's structural.
Pattern drift is real. When the AI generates the 15th service and you've subtly changed the pattern since the 5th service, you end up with inconsistencies. The fix: update the pattern files religiously. If the pattern changes, the pattern file changes first.
Context limits matter. A single session can't hold the entire codebase in its head. Complex cross-service changes require careful sequencing — modify commons first, then the services that depend on it, then the Helm charts, then the deployment scripts. The AI needs to be guided through these sequences; it can't always discover the optimal order on its own.
Over-engineering is the default. Ask an AI to "add error handling" and you'll get three layers of retry logic, custom exception hierarchies, and fallback mechanisms for scenarios that can't happen. We had to explicitly train the AI (through CLAUDE.md rules) to keep solutions simple and focused.
What We Got Right
Lessons become rules become prevention. Every significant bug got codified as a rule with a "STOP CHECK." After 845 commits, the same mistakes rarely happen twice. The AI partner carries forward every lesson from every failure, permanently.
Patterns scale linearly. The 25th service took roughly the same effort as the 5th, because the patterns, commons libraries, and conventions were established. In a traditional team, the 25th service often takes more effort due to accumulated technical debt and context loss from team turnover.
Documentation compounds. The documentation we wrote for the first five services made the next twenty faster. The AI reads the docs, understands the conventions, and generates consistent code. The investment pays dividends on every subsequent feature.
Scripts eliminate classes of errors. Forbidden commands + mandatory scripts = no ad-hoc infrastructure changes. When the AI uses service-build-deploy.sh instead of raw Docker and Helm commands, it inherits all the validation, error handling, and rollback logic we've built into those scripts.
Advice for Teams Considering AI Pair Programming
If you're thinking about using AI coding assistants for serious software development (not just autocomplete, but actual pair programming), here's what we'd tell you:
Invest in your CLAUDE.md (or equivalent) before you invest in code. The quality of your AI partner's output is directly proportional to the quality of your instructions. Spend the first week writing conventions, patterns, and rules. It pays back tenfold.
Codify lessons, not just code. When something goes wrong, don't just fix it — write the rule that prevents the entire category of failure. Your AI partner will follow rules it can read. It can't follow lessons it doesn't know about.
Verify against reality, not assumptions. The AI doesn't know which CLI flags exist in version 2.3.1 of a tool. It doesn't know that a Docker image runs as UID 1001, not root. Build verification steps into your process.
Use the AI for what it's good at. Pattern replication, boilerplate generation, documentation, test scaffolding, consistency enforcement. Don't use it for architectural decisions, security design, or novel algorithm development — those still need human judgment.
Keep humans in the loop for judgment calls. The AI can generate 25 services. A human needs to decide if 25 is the right number. The AI can implement a caching strategy. A human needs to decide if caching is the right approach. Architecture is still a human discipline.
"The computer was born to solve problems that did not exist before." — Bill Gates
AI pair programming doesn't solve the problem of building software. It solves the problem of building software slowly. The thinking, the design, the judgment — that's still you. But the translation from thought to code, the replication of patterns, the enforcement of conventions, the accumulation of knowledge? That's where the AI earns its keep.
What's Next
This is the final post in the eight-part series. We started with a question — What if your data platform spoke your language? — and worked our way through architecture, semantics, memory, agents, processing, security, and now the story of building it all.
Matih is a bet that the era of stitching together 15 tools with YAML and prayer is ending. That the distance between a business question and a data answer should be measured in seconds, not sprints. That security and governance should be structural, not procedural. And that AI is ready to be not just a feature of the platform, but a partner in building it.
The platform is live. The conversation is open. Ask it something.
About Matih: Matih is a cloud-agnostic, Kubernetes-native platform that unifies Data Engineering, Machine Learning, Artificial Intelligence, and Business Intelligence into a single system with a conversational interface at its core. Learn more at matih.ai (opens in a new tab).
Tags: #ClaudeCode #AIPairProgramming #SoftwareEngineering #DeveloperExperience #Microservices #Enterprise #BuildInPublic #AI #DevTools
Previous: Enterprise-Grade Without Enterprise Pain: Security, Governance, and Trust First in series: Intent to Insights: Why Your Data Stack Needs a Conversational Brain